バックエンドサービスのテストコード [API仕様ファースト開発]
バックエンドサービスを開発する際に、そのバックエンドサービスがデータベースと接続して独自のデータを保持していることが多いです。そのようなバックエンドサービスをテストするためのテーストコードの作成において、テスト対象の機能をテストするために、事前にデータベースへデータを設定する必要があります。
API仕様ファースト開発でE2Eテストフレームワークを構築してからE2Eテストを作成する場合、サービスを一から開発するのであれば、最初はある程度、データベースへ直接データを設定する必要があります。なぜなら、必要なデータを設定するためのエンドポイントがまだ実装されていないかもしれないからです。ある程度エンドポイントの実装が進めば、既存のエンドポイントを呼び出してデータを整備することが可能になっていきます。
しかし、単体テストや内部の機能テストとして、テストコードを作成すると、必要なデータをテストコードから直接データベースへ設定してテストが作成されることも多いと思います。そして、すべてのテストが同じように作成されてしまうこともあるかと思います。
テストコードで以下の処理を行っていると、テストを並列に実行できません。
このような処理を行っているテスト群を作り続けていると、テストを並列実行できずに、逐次実行していく必要があるため、すべてのテストの実行が完了するのに30分を超えてしまうことも珍しくなくなります。
API仕様ファースト開発でE2Eテストフレームワークを構築してからE2Eテストを作成する場合、サービスを一から開発するのであれば、最初はある程度、データベースへ直接データを設定する必要があります。なぜなら、必要なデータを設定するためのエンドポイントがまだ実装されていないかもしれないからです。ある程度エンドポイントの実装が進めば、既存のエンドポイントを呼び出してデータを整備することが可能になっていきます。
しかし、単体テストや内部の機能テストとして、テストコードを作成すると、必要なデータをテストコードから直接データベースへ設定してテストが作成されることも多いと思います。そして、すべてのテストが同じように作成されてしまうこともあるかと思います。
データベースへの直接設定する問題点
テストコードからデータベースへ直接レコードを挿入する場合、サービスの成長い伴ってテーブルが発展していく際に、以下の問題が発生します。- レコードのカラム変更(追加、削除、型の修正、etc)が行われた際に、すべてのテストコードが正しく対応できていない可能性がある
- エンドポイント経由ではないため、正しくないレコードが作られている可能性がある
テストを並列に実行できない要因
バックエンドサービスの機能が増えていけば、テストコードも増えてきます。エンドポイントを直接呼び出すE2Eテストであれば、テストコードを並列に実行しても問題ないはずです。しかし、個々のテストが必要なデータを直接データベースへ設定するテスト群では、並列に実行できない場合があります。テストコードで以下の処理を行っていると、テストを並列に実行できません。
- レコードをINSERTする際に、プライマリーキーをハードコードして指定している
- テーブルが空である必要があるテストとなっており、個々のテストの実行で、最初にテーブル内のレコードをすべて削除している
save()を呼び出した際に、すでにレコードが存在していれば更新になってしまいます。このような処理を行っているテスト群を作り続けていると、テストを並列実行できずに、逐次実行していく必要があるため、すべてのテストの実行が完了するのに30分を超えてしまうことも珍しくなくなります。
まとめ
私自身は、バックエンドサービスを開発してきて、開発を担当するサービス用のテストコードへの信頼を失うような開発はしたくないですし、手元の開発マシンですべてのテーストを短時間に実行しながら開発するのを好みます。つまり、テストコードからデーターベースへ事前データを直接設定するのは避けた方がよいですし、テストコードは並列に実行できた方がよいです。2024-03-15 07:29
コメント(0)
公開API経由のテスト [API仕様ファースト開発]
「API仕様ファースト開発」では、バックエンドサービスが提供するフロントエンド向けのAPIの仕様を策定して、そのAPI仕様に記述されたエンドポイントを直接呼び出すE2Eテストを作成していきます。つまり、バックエンドサービスの公開API経由のテストとなります。
公開API経由のテストに関しては、『Googleのソフトウェアエンジニアリング』の12.2.2「公開API経由のテスト」に記述されています。そこからいくつか抜粋して紹介します。

公開API経由のテストに関しては、『Googleのソフトウェアエンジニアリング』の12.2.2「公開API経由のテスト」に記述されています。そこからいくつか抜粋して紹介します。
Googleのソフトウェアエンジニアリング ―持続可能なプログラミングを支える技術、文化、プロセス
- 出版社/メーカー: オライリージャパン
- 発売日: 2021/11/29
- メディア: 単行本(ソフトカバー)
テスト対象システムの要件が変化しない限りテストが変化する必要がないことを保証するためのプラクティスをいくつか見ていこう。このことを保証するのに群を抜いて最も重要な方法は、テスト対象システムのユーザーが呼び出すのと同じ方法でシステムを呼び出すテストを書くことである。それはつまり、システムの実装の内部的詳細部分ではなく、システムの公開APIに対して呼び出しを行うということだ。
公開APIのみを利用するテストは定義上、テスト対象システムに、そのシステムのユーザーがアクセスするのと同じやり方でアクセスする。そのようなテストは明示的な契約を結ぶので、より現実的であり、脆さがより低い。つまり、そのようなテストが破綻するなら、システムの既存ユーザーの活動もまた破綻するだうということを必然的に意味する。それらの契約のみをテストするというのは要するに、テストにつまらない変更を加えた結果についていちいち心配する必要なしに、システム内部のリファクタリングはどんなものでもやりたいようにやれるということだ。
Googleでは、公開API経由のテストは実装詳細に対するテストより優れているという点を納得させるために、エンジニアを説得しなければならない場合があることがわかっている。エンジニアの気が進まないのは理解できる。自分が書いたばかりのコードに専念するテストを書く方が、そのコードがシステム全体にどう影響するか理解するよりずっと楽な場合が多いのだ。それにもかかわらず、そのようなプラクティの奨励には価値があることがわかっている。そのプラクティスに従うという追加的な労力を先行して費やすと、保守の負担が減るという形で、かけた労力の何倍もの見返りがある。公開APIに対するテストは、行うことでテストの脆さが完璧に防げるわけではない。しかし、システムに対して意味のある変更が起こった場合のみテストが失敗するよう担保するために行える対策として、最も重要なのは、公開APIに対するテストだ。
2024-02-20 06:55
コメント(0)
Mission Abandoned [API仕様ファースト開発]
2017年8月末に株式会社リコーを退職し、ソラミツ、メルペイ、カウシェとバックエンドサービス開発に従事してきました。最初の頃は、初めてのバックエンドサービス開発なので、どのように行うのがよいのかは手探りに近かったのですが、メルペイで現在も運用されているマイクロサービスの1つを開発してから、さまざまなバックエンドサービス開発を通して、得た知見や行ってきたことを雑誌の書籍やTechブログとしてまとめてきました。その主なものは次の通りです。

記事「実践API設計」では、E2Eテストを書いて実際にどのコードが実行されたのかをカバレッジで確認することも重要だと述べています。
しかし、これらを全く行っていなくても、サービスの開発はできます。だから、経験していない開発者が多数いるわけです。今回は、きちんと経験した開発者を増やして、私が健全だと思う開発プロセス構築を目指すというMissionはAbandonedとなります。
- 「API仕様ファースト開発」
- 1つのサービスを単独でテストするE2EテストフレームワークとE2Eテストの整備
- 出版社/メーカー: 技術評論社
- 発売日: 2023/04/22
- メディア: Kindle版
記事「実践API設計」では、E2Eテストを書いて実際にどのコードが実行されたのかをカバレッジで確認することも重要だと述べています。
しかし、これらを全く行っていなくても、サービスの開発はできます。だから、経験していない開発者が多数いるわけです。今回は、きちんと経験した開発者を増やして、私が健全だと思う開発プロセス構築を目指すというMissionはAbandonedとなります。
2024-02-18 06:58
コメント(0)
健全なバックエンドサービス開発 [API仕様ファースト開発]
ウェブサービスのバンクエンドサービス開発に従事してすでに6年以上経過しています。そして、最初から「API仕様ファースト開発」を行っています。「API仕様ファースト開発」は、私自身の造語です。
バックエンドサービスを開発する際に、(無意識に)私にとって当然だと思っていたのは次の2つです。
一般的には、単体テスト・結合テストを開発しながらソフトウェアは行うと考えられていますが、上記2点を優先して開発した場合、E2Eテストが実行されて、カバレッジが確認できれば、そこからあえて、単体テストや結合テストを書くことはしません。
なぜなら、常に、API仕様に基づいてテストファーストでE2Eテストを開発し、その後実装することを行っているからです。E2Eテストですでに機能の確認が行われていれば、さらに単体テストや結合テストを作成することは無駄であり、その工数を費やすことに意味がないからです。
私自身は、過去2回行ったテスト駆動開発によるデジタル複合機のコントローラソフトウェア開発(通算、約6年)でもテストコードはすべてAPI仕様に記述された呼び出しポイントを呼び出すテストを書いたり、書くことを指導してきました。その経験から、ウェブサービスのバンクエンドサービス開発に従事するようになっても、最初に述べた2点を優先して、当然だと思ってきました。
バックエンドサービスを開発する際に、(無意識に)私にとって当然だと思っていたのは次の2つです。
この2つが最初にありきなので、実際のバックエンドサービスの構造をどうするのか、内部の各モジュールのテストをどうするのかといったことは、最優先とはなりません。
- フロントエンドを提供するバックエンドサービスのAPIでは、その仕様をきちんと記述する
- API仕様通りに個々のエンドポイントが動作するかを検証する自動テスト(E2EテストフレームワークとE2Eテスト)を整備する
一般的には、単体テスト・結合テストを開発しながらソフトウェアは行うと考えられていますが、上記2点を優先して開発した場合、E2Eテストが実行されて、カバレッジが確認できれば、そこからあえて、単体テストや結合テストを書くことはしません。
なぜなら、常に、API仕様に基づいてテストファーストでE2Eテストを開発し、その後実装することを行っているからです。E2Eテストですでに機能の確認が行われていれば、さらに単体テストや結合テストを作成することは無駄であり、その工数を費やすことに意味がないからです。
私自身は、API仕様を記述せずに、1つのバックエンドサービスとしてそのエンドポイントを直接呼び出す自動テストコードも存在しないことが正しい開発だと思わないだけです。私は、そのような開発をしていたら、不快に思うだけです。
不健全なバックエンドサービス開発
私にとって不健全に思われるバックエンドサービス開発は、次の通りです。- API仕様が記述されず、バックエンドサービスのエンドポイントのテストはフロントエンドを接続して手作業で行う開発。
- 仮にAPI仕様が記述されていたとしても、バックエンドサービスのエンドポイントのテストはフロントエンドを接続して手作業で行う開発。
- 単体テストや結合テストでテストしてるから「大丈夫なはず」という開発。
- API仕様が記述されているなら、バックエンドサービスのエンドポイントを直接呼び出すE2Eテストで検証する方が素直
- API仕様が記述されていない場合、単体テストや結合テストの妥当性をきちんと確認する方法がない
私自身は、過去2回行ったテスト駆動開発によるデジタル複合機のコントローラソフトウェア開発(通算、約6年)でもテストコードはすべてAPI仕様に記述された呼び出しポイントを呼び出すテストを書いたり、書くことを指導してきました。その経験から、ウェブサービスのバンクエンドサービス開発に従事するようになっても、最初に述べた2点を優先して、当然だと思ってきました。
2024-02-10 11:10
コメント(0)
API仕様の技術的負債の返済で遭遇する問題 [API仕様ファースト開発]
API仕様の技術的負債が積み上がっている「言い訳」の一つに次のようなものがあります。
本当にそうでしょうか。また、テストに関しても、バックエンドサービスのAPIのエンドポイントを直接呼び出してテストするE2Eテストはなく、単体テストやモックを駆使した結合テストしかなくて、最終的な動作はフロントエンドを使って手作業で確認していることがあります。さらに、これらのテストも開発担当者任せになっていることがあるかもしれません。
開発者担当者任せになっていても、「テストが書かれていて、そのテストがCIで実行されてPASSしたものだけがマージされる」という今日では最低となる基準は満たすことになります。そして、さまざまなサービスを「爆速」で開発していると外部に対して宣伝しているかもしれません、
E2Eテストフレームワークを構築したら、次は、既存のエンドポイントの修正を通して、技術的負債を返済するか、新たなエンドポイントをきちんと開発するかのどちらかです。どちらの場合も、開発組織へ新たに参加した開発者が実際に行ってみると遭遇する問題があります。それは、次のことです。
既存のエンドポイントの修正であれば、すでにコードが存在するので、「既存のコードにバグがあり」ということはあります。では、新たなエンドポイントの作成ではどうでしょうか。
新たなエンドポイント用のE2Eテストにおいて、事前準備として既存のエンドポイントを呼び出してデータを作成する際に、期待通りに作成されないというバグに遭遇することがあります(作成されているようだが、エンドポイントの呼び出しのレスポンスで作成されたデータが正しく返ってこないとか)。
私自身が経験したこととしては、作成されたデータがレスポンスで期待通りに返ってこないというものです。GraphQLでは、要求しないと値が返ってこないので、すべてのフィールドを要求するようなクエリを書いて呼び出すと一部のフィールドが返ってこないというものです。
このような場合、新たなエンドポイントの実装に入る前に、既存のエンドポイントのバグを調査することになります。そして、見知らぬコードの世界で、バグの原因を見つけるのに数時間を費やすことになるのです。
この場合、新たに作成しているE2Eテスト内でそのバグの再現テストは作成していることになります。つまり、期待通りのレスポンスが返ってこないので、本当に作成されたのか分からず、テストが失敗するようになっていればよいです。
バグの原因を見つけたら、それを修正して、E2Eテスト内のデータを準備する部分がPASSするのを確認すればよいわけです。ところが、この実装の修正によって、次のどちらかが発生します。
(1990年代まで当たり前であった)実装からテストまですべて開発担当者任せになっているサービスでは、このような問題に遭遇して、既存のバグ調査だけで1日が終わってしまってもおかしくはないです。
バックエンドサービスとそれに対応するフロントエンドサービスを同じソフトウェアエンジニアが開発しているので、API仕様を書く必要がない。
本当にそうでしょうか。また、テストに関しても、バックエンドサービスのAPIのエンドポイントを直接呼び出してテストするE2Eテストはなく、単体テストやモックを駆使した結合テストしかなくて、最終的な動作はフロントエンドを使って手作業で確認していることがあります。さらに、これらのテストも開発担当者任せになっていることがあるかもしれません。
開発者担当者任せになっていても、「テストが書かれていて、そのテストがCIで実行されてPASSしたものだけがマージされる」という今日では最低となる基準は満たすことになります。そして、さまざまなサービスを「爆速」で開発していると外部に対して宣伝しているかもしれません、
技術的負債の返済で遭遇する問題
API仕様の技術的負債の返済には、次の二つを最初に行う必要があります。- API仕様の書き方を決める
- E2Eテストフレームワークを構築する
E2Eテストフレームワークを構築したら、次は、既存のエンドポイントの修正を通して、技術的負債を返済するか、新たなエンドポイントをきちんと開発するかのどちらかです。どちらの場合も、開発組織へ新たに参加した開発者が実際に行ってみると遭遇する問題があります。それは、次のことです。
既存のコードにバグがあり、期待どおりに動作しない。そのため、その原因の調査に時間を要する。
既存のエンドポイントの修正であれば、すでにコードが存在するので、「既存のコードにバグがあり」ということはあります。では、新たなエンドポイントの作成ではどうでしょうか。
データの準備で躓く
新たなエンドポイントを作成する場合、そのエンドポイントを呼び出すための前提条件として、必要なデータをあらかじめDBに作成する必要があります。サービスを新規に立ち上げるのでなければ、そのようなデータを作成するための既存のエンドポイントは存在することが多いです。だだし、API仕様が書かれていなくて、E2Eテストも存在しないでしょう。新たなエンドポイント用のE2Eテストにおいて、事前準備として既存のエンドポイントを呼び出してデータを作成する際に、期待通りに作成されないというバグに遭遇することがあります(作成されているようだが、エンドポイントの呼び出しのレスポンスで作成されたデータが正しく返ってこないとか)。
私自身が経験したこととしては、作成されたデータがレスポンスで期待通りに返ってこないというものです。GraphQLでは、要求しないと値が返ってこないので、すべてのフィールドを要求するようなクエリを書いて呼び出すと一部のフィールドが返ってこないというものです。
このような場合、新たなエンドポイントの実装に入る前に、既存のエンドポイントのバグを調査することになります。そして、見知らぬコードの世界で、バグの原因を見つけるのに数時間を費やすことになるのです。
この場合、新たに作成しているE2Eテスト内でそのバグの再現テストは作成していることになります。つまり、期待通りのレスポンスが返ってこないので、本当に作成されたのか分からず、テストが失敗するようになっていればよいです。
バグの原因を見つけたら、それを修正して、E2Eテスト内のデータを準備する部分がPASSするのを確認すればよいわけです。ところが、この実装の修正によって、次のどちらかが発生します。
- 既存の単体テスト(や結合テスト)が失敗する
- あるいは、既存の単体テスト(や結合テスト)が何も失敗しない
(1990年代まで当たり前であった)実装からテストまですべて開発担当者任せになっているサービスでは、このような問題に遭遇して、既存のバグ調査だけで1日が終わってしまってもおかしくはないです。
2024-02-07 03:28
コメント(0)
Pull Requestと「謙虚、尊敬、信頼」 [API仕様ファースト開発]
Googleのソフトウェアエンジニアリング ―持続可能なプログラミングを支える技術、文化、プロセス
- 出版社/メーカー: オライリージャパン
- 発売日: 2021/11/29
- メディア: 単行本(ソフトカバー)
一年半前に読んだ本ですが、あらために2章「チームでうまく仕事をするには」を読み返してみると最初に、次のように述べられています。
本章において決定的に重要な考え方は、ソフトウェア開発とはチームによる取り組みであるということだ。そして、エンジニアリングのチームで(あるいは他のどんな創造的共同作業でも)成功するためには、「謙虚、尊敬、信頼」という中心的原則をめぐる自身の行動を改革する必要がある。
また、9章「コードレビュー」(p.197)からの抜粋ですが、コードの変更については次のように述べられています。
変更にLGTMの印が付いた後で、作者はその変更をコードベースへコミットすることを許されるが、それは作者が全コメントを解決し、その変更が承認されることを条件としている.GoogleでのコードレビューのプロセスはGitHubを使ったPull Requestとは異なりますが、基本的には承認されることが条件となります。
私自身がGitHubを仕事で使うようになったのは、2017年9月からソラミツで働き始めてからでした。それから、メルペイ、カウシェと働いてきましたが、PRをdevelopブランチやstagingブランチへマージするには承認(approve)が必須でした。
チームの他のメンバーにレビューを依頼し、コメントを通した指摘の内容を理解して、適切な対処(コードの修正やコメントを通した説明、etc)をして、承認されてから、そのPRをマージするということです。そして、重要なのは、個々のソフトウェアエンジニアの役割(アーキテクト、テックリード、チームリーダー、etc)に関係なく、同等に承認を必要とする運用です。
もちろん、レビューしてもらって承認してもらったからと言って、完璧なコードであることが保証されたわけではありません。そうではなく、「チームによる取り組み」として、このようなプロセスを行い、集団的英知を増やし「バス係数」(プロジェクトを完全に破綻させるために必要な、バスに轢かれる人の数)を高めることになります。
しかし、このような運用ではなく、ソフトウェアエンジニアの役割によっては、レビューしてもらう必要も承認も必要とせずにPRをマージできるが、他のソフトウェアエンジニアはレビューと承認を必要とする運用ではどうでしょうか。PRの承認を要求される役割のソフトウェアエンジニアにとって、承認なしでマージされるPRすべてがベストプラクティスのようなお手本であれば、おそらく何も問題はないかもしれません。しかし、何を行っているのか分かりにくコードだったり、十分なテストコードが書かれていなかったり、必要な説明が書かれていなかったりするかもしれません。
あるいは、きちんとレビューして、コメントをしたにもかかわらず、コメントに対する修正内容を再度確認することを依頼されることなく、PRの作成者の判断でマージされたらどうでしょうか。そうなると、次からはきちんとレビューする気が失せるかもしれません。このようなことが起きないように、レビューと承認を必要とするプロセスをチーム全体で運用するわけです。
一部のソフトウェアエンジニアだけが、Pull Requestを承認なしでマージできる運用は、長期的な視点では「謙虚、尊敬、信頼」を破壊するベストプラクティスかもしれません。
2024-02-04 06:08
コメント(0)
API仕様ファースト開発(2) [API仕様ファースト開発]
よく知られている「Be the Worst」(最低である)は、以下の書籍で述べられています。

")
『情熱プログラマー』の「一番の下手くそでいよう」では、次のように述べられています。
優れた開発者の定義には、おそらくいくつかの側面があります。たとえば、次の二つもそれらに含まれると思います。
ソフトウェアエンジニアリングとして優れた方法を実践しているのかにも、さまざな側面があります。たとえば、継続的インテグレーションを行うことは、今日では当たり前ですが、残念ながら今でもできていない多くの開発組織が存在するのではないかと思います。
あるいは、「API仕様ファースト開発」で述べたような開発プロセスを実践できている組織と全くできていない組織では、どちらの組織に参加するかによって、成長は大きく異なってきます。
ソフトウェアエンジニアリングとして優れた方法を試したり、導入したりするのは、実はあまり簡単ではありません。私自身の過去の経験からしても、従来の方法を変えることに対する現場のエンジニアの抵抗(というより慣性)により、開発現場からの自発的な改善には結びつかないことが多いです。
リコーを退職する以前の富士ゼロックスやリコーでの開発では、強い権限を持つ立場(たとえば、開発の部門長という立場)を利用して、さまざなことを強制して改善させることが多かったです。リコーを退職後は、いわゆるスタートアップ企業で1人のソフトウェアエンジニアとして働いているので、「API仕様ファースト開発」などは「まずはやってみせる」というところか始まります。そして、実際に改善するかしないかは、組織のメンバー次第です。
- 出版社/メーカー: オーム社
- 発売日: 2017/07/15
- メディア: Kindle版
アプレンティスシップ・パターン ―徒弟制度に学ぶ熟練技術者の技と心得 (THEORY/IN/PRACTICE)
- 出版社/メーカー: オライリージャパン
- 発売日: 2010/07/08
- メディア: 単行本(ソフトカバー)
『情熱プログラマー』の「一番の下手くそでいよう」では、次のように述べられています。
『アプレンティスシップ・パターン』の「最低である(Be the Worst)」では次のように述べられています。君の周りにいる人たちが君自身のパフォーマンスに影響する。
仲間は慎重に選べ
あなたより優れた開発者に囲まれるようにしてください。あなたが最低のメンバーであり、成長する余地がある、より強力なチームを見つけてください。
優れた開発者の定義には、おそらくいくつかの側面があります。たとえば、次の二つもそれらに含まれると思います。
- 使っている技術に関して深く熟知している
- ソフトウェアエンジニアリングとして優れた方法を実践している
ソフトウェアエンジニアリングとして優れた方法を実践しているのかにも、さまざな側面があります。たとえば、継続的インテグレーションを行うことは、今日では当たり前ですが、残念ながら今でもできていない多くの開発組織が存在するのではないかと思います。
あるいは、「API仕様ファースト開発」で述べたような開発プロセスを実践できている組織と全くできていない組織では、どちらの組織に参加するかによって、成長は大きく異なってきます。
ソフトウェアエンジニアリングとして優れた方法を試したり、導入したりするのは、実はあまり簡単ではありません。私自身の過去の経験からしても、従来の方法を変えることに対する現場のエンジニアの抵抗(というより慣性)により、開発現場からの自発的な改善には結びつかないことが多いです。
リコーを退職する以前の富士ゼロックスやリコーでの開発では、強い権限を持つ立場(たとえば、開発の部門長という立場)を利用して、さまざなことを強制して改善させることが多かったです。リコーを退職後は、いわゆるスタートアップ企業で1人のソフトウェアエンジニアとして働いているので、「API仕様ファースト開発」などは「まずはやってみせる」というところか始まります。そして、実際に改善するかしないかは、組織のメンバー次第です。
2024-01-07 11:59
コメント(0)
API仕様ファースト開発 [API仕様ファースト開発]
「API仕様ファースト開発」という用語は、私自身が雑誌「WEB+DB PRESS Vol.134」の特集1「実践API設計」を執筆する際に考えた造語です。
全く新規にサービスを開発する場合の開発順序は次のようになります(記事の題3章の図1)。
これは、私自身が初めてメルペイで担当して、一からマイクロサービスを開発したときの開発順序です。そして、その後、チーム移動により別のマイクロサービスの開発へ移動したり、カウシェへ転職したりした際に、最初に導入したのはE2Eテストフレームワーク(記事の第4章「E2Eテストフレームワークの構築」)でした。
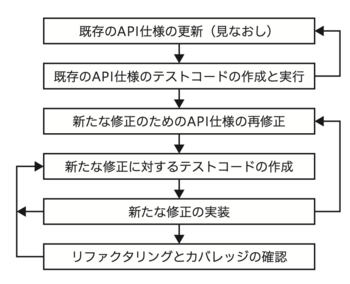
そして、API仕様の技術的負債(エンドポイントの仕様が書かれていなくて、それをテストするE2Eテストもない状態)を返済するために、次の開発順序(記事の第5章の図1)を自分自身も行い、他の開発者達にも行ってもらうようになりました。
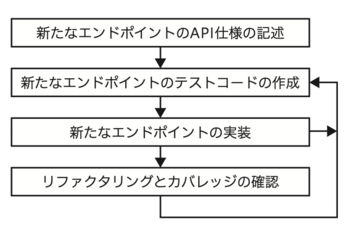
新たなエンドポイントの追加の場合は、次の開発順序(記事の第5章の図2)となります。
この開発プロセスが定着すると、バックエンドサービスの既存のエンドポイントの修正や新規のエンドポイントの追加の際に、最初に行われるのは次のようになります。
この開発プロセスが定着すると、次のようなことが利点として発生します。
さらに、このような開発手順が定着して日々行われている開発組織に、同じ経験がない開発者が新たに加わった場合でも、次のようになるはずです。
結果として、API仕様ファースト開発経験がない開発者が開発組織に加わっても、かなり早い段階で、API仕様ファースト開発を行うようになり、API仕様の技術的負債を積み上げることはなくなります。つまり、開発者の増加に対して、スケールアップする組織となっていきます。
逆の状況では、API仕様の記述がなく、API仕様に基づくE2Eテストがないまま開発していると、API仕様の技術的負債を積み上げていくだけです。そして、新たな開発者が加わっても、API仕様ファースト開発経験がない開発者なら、技術的負債を返済することなく積み上げるだけとなってしまいます。
全く新規にサービスを開発する場合の開発順序は次のようになります(記事の題3章の図1)。
図1 API仕様ファースト開発での開発順序
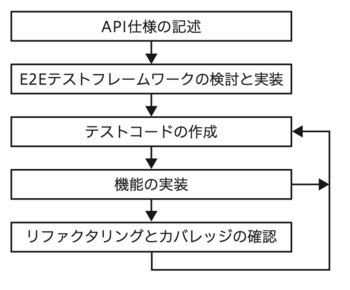
これは、私自身が初めてメルペイで担当して、一からマイクロサービスを開発したときの開発順序です。そして、その後、チーム移動により別のマイクロサービスの開発へ移動したり、カウシェへ転職したりした際に、最初に導入したのはE2Eテストフレームワーク(記事の第4章「E2Eテストフレームワークの構築」)でした。
そして、API仕様の技術的負債(エンドポイントの仕様が書かれていなくて、それをテストするE2Eテストもない状態)を返済するために、次の開発順序(記事の第5章の図1)を自分自身も行い、他の開発者達にも行ってもらうようになりました。
図1 既存のエンドポイントの修正順序
新たなエンドポイントの追加の場合は、次の開発順序(記事の第5章の図2)となります。
図2 新たなエンドポイントの追加順序
この開発プロセスが定着すると、バックエンドサービスの既存のエンドポイントの修正や新規のエンドポイントの追加の際に、最初に行われるのは次のようになります。
- 仕様の修正のPR(Pull Request)の作成(新規の場合、新規の仕様のPR)
- 主にフロントエンド開発者による仕様PRのレビューとフィードバック(そして、承認)
- バックエンド開発(E2Eテスト修正・作成およ実装)
- バックエンド開発者によるテストコードと実装のPRのレビュー、フィードバック、承認
この開発プロセスが定着すると、次のようなことが利点として発生します。
- フロントエンド開発者は、バックエンドのAPI仕様がきちんと記述されていることを期待し、不明点や不足点は仕様に反映される。つまり、ミーティングで口頭で聞いたり、Slackで問い合わせただけの状態にならないようになります。
- バックエンド開発者も、たとえ自分で過去に担当して開発してエンドポイントであっても、その詳細を忘れることはよく発生します。その場合、実装を読み直すことなく、API仕様を確認できる。結果として、問い合わせがあった時に、実装を読み直す必要がなくなります。
- 新たにチームに加わったしたフロントエンドおよびバックエンドの開発者は、個々のエンドポイントの仕様を、他のバックエンド開発者に問い合わせることなく理解できます。
さらに、このような開発手順が定着して日々行われている開発組織に、同じ経験がない開発者が新たに加わった場合でも、次のようになるはずです。
- API仕様を記述しないで仕様のPRを出しても却下される。たとえば、gRPCであれば、.protoファイルにメッセージ定義しかなく、何も説明が書かれていなかったり、記述されていなかったりする。GraphQLでは、Mutationの新たなエンドポイントのtype定義はあるが、何も仕様が記述されていないとか。
- 実装のPRに、エンドポイントの仕様に基づくE2Eテストが書かれていない場合、却下される。
結果として、API仕様ファースト開発経験がない開発者が開発組織に加わっても、かなり早い段階で、API仕様ファースト開発を行うようになり、API仕様の技術的負債を積み上げることはなくなります。つまり、開発者の増加に対して、スケールアップする組織となっていきます。
逆の状況では、API仕様の記述がなく、API仕様に基づくE2Eテストがないまま開発していると、API仕様の技術的負債を積み上げていくだけです。そして、新たな開発者が加わっても、API仕様ファースト開発経験がない開発者なら、技術的負債を返済することなく積み上げるだけとなってしまいます。
- 出版社/メーカー: 技術評論社
- 発売日: 2023/04/22
- メディア: Kindle版
2023-12-07 06:17
コメント(0)
E2Eテスト vs E2Eテスト [API仕様ファースト開発]
私が「WEB+DB PRESS, Vol.134」の特集1「実践API設計」の中で使っている用語「E2Eテスト」は、一般的な書籍で述べられているE2Eテストとは若干異なります。
どのように違うのかをウェブサービスのバックエンドのサービスで説明します。新たに図を起こすのが面倒なので、すでにある記事「マイクロサービスの開発とテストファースト/テスト駆動開発」からそのまま引用します。

この図では、「加盟店管理用APIマイクロサービス」が複数のマイクロサービスに依存しています。
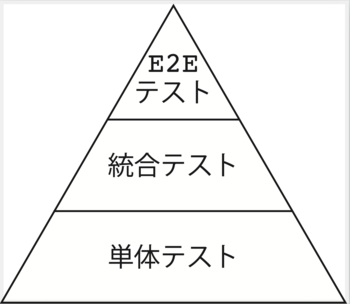
テストピラミッドの例
このテストピラミッドでは、「統合テスト」は、依存しているサービスへの呼び出し部分をモックで置き換えてサービス単体でテストすることを指すことが多いです。したがって、依存しているサービスへの呼び出しを、テスト時だけモックで置き換えられるような仕組みを埋め込む必要があります。つまり、本番環境で動作するコードの動作を確認しているわけではありません。
たとえば、実際に本番環境(もしくは開発用環境)で依存するサービスを呼び出したら、呼び出しコードに間違いがあり、モックとは異なる動作をしたり、正しく動作しなかったりする可能性があります。
そのため、統合テストの次の上の段階で行いたいのは、テスト対象のサービスの実行ファイル(本番環境にデプロイするバイナリ形式)で実際に実行して、そのAPIのエンドポイントを外部から呼び出すテストを行うことになります。
この時に、依存するサービスをどうするのかという問題に直面することになります。その結果、一般的な書籍で述べられている「E2Eテスト」ということになります。しかし、それは他の依存するサービスも動作させないといけないし、それらのサービスが動作するためのデータベースの設定が必要かもしれなく、設定が非常に面倒になります。
その結果、一般的な書籍では、E2Eテストは構築が難しいくテスト時間も要するので、単体テストや統合テストを強く勧めています。
当時は、ほぼすべてのマイクロサービスが同時に開発されており、私が担当するマイクロサービスが依存するマイクロサービスも開発中という状態でした。それで考え出したE2Eテストです。
考え出した背景は、次の通りです。
2019年12月14日に開催されたGDG DevFest Tokyo 2019で最初の発表を行っています。
どのように違うのかをウェブサービスのバックエンドのサービスで説明します。新たに図を起こすのが面倒なので、すでにある記事「マイクロサービスの開発とテストファースト/テスト駆動開発」からそのまま引用します。
この図では、「加盟店管理用APIマイクロサービス」が複数のマイクロサービスに依存しています。
一般的なE2Eテストとは
一般的な書籍では、テストピラミッドにおける頂点にあるE2E(End-To-End)テストは、「加盟店管理用APIマイクロサービス」およびそれが依存するすべてのマイクロサービスを何らかの環境(たとえば、Docker、あるいは開発用のクラウド環境)にデプロイして「加盟店管理用APIマイクロサービス」をテストすることを指すものが多いです。テストピラミッドの例
このテストピラミッドでは、「統合テスト」は、依存しているサービスへの呼び出し部分をモックで置き換えてサービス単体でテストすることを指すことが多いです。したがって、依存しているサービスへの呼び出しを、テスト時だけモックで置き換えられるような仕組みを埋め込む必要があります。つまり、本番環境で動作するコードの動作を確認しているわけではありません。
たとえば、実際に本番環境(もしくは開発用環境)で依存するサービスを呼び出したら、呼び出しコードに間違いがあり、モックとは異なる動作をしたり、正しく動作しなかったりする可能性があります。
そのため、統合テストの次の上の段階で行いたいのは、テスト対象のサービスの実行ファイル(本番環境にデプロイするバイナリ形式)で実際に実行して、そのAPIのエンドポイントを外部から呼び出すテストを行うことになります。
この時に、依存するサービスをどうするのかという問題に直面することになります。その結果、一般的な書籍で述べられている「E2Eテスト」ということになります。しかし、それは他の依存するサービスも動作させないといけないし、それらのサービスが動作するためのデータベースの設定が必要かもしれなく、設定が非常に面倒になります。
その結果、一般的な書籍では、E2Eテストは構築が難しいくテスト時間も要するので、単体テストや統合テストを強く勧めています。
私が定義しているE2Eテストとは
私がマイクロサービスの開発とテストファースト/テスト駆動開発」や「WEB+DB PRESS, Vol.134」の特集1「実践API設計」で述べているE2Eテストは、テスト対象のサービスの実行ファイル(本番環境にデプロイするバイナリ形式)で実際に実行して、そのAPIのエンドポイントを外部から呼び出すテストを行うのですが、以下の点が異なります。- 本物の依存するサービスは使わない
- 開発者の開発PC(たとえば、MacBook Pro)上でローカルにテストが実行できる
必要に迫られて開発した方法
2018年6月にメルペイに入社して、本格的にウェブサービスのバックエンドサービスの開発に従事するようになって担当したのが、上の図にある「加盟店管理用APIマイクロサービス」です。当時は、ほぼすべてのマイクロサービスが同時に開発されており、私が担当するマイクロサービスが依存するマイクロサービスも開発中という状態でした。それで考え出したE2Eテストです。
考え出した背景は、次の通りです。
- 自分が開発を担当するマイクロサービスの開発・テストが終わったと責任を持って言えるようにするにはどうすればよいか
- マイクロサービスが定義しているAPIの仕様に書かれている動作をすべて自動テストで確認してから、フロントエンドの担当者に、マイクロサービスの開発が終わっているので使ってくださいと言いたい
2019年12月14日に開催されたGDG DevFest Tokyo 2019で最初の発表を行っています。
〓GDG DevFest Tokyo 2019 ご登壇者紹介〓
— GDG Tokyo (@gdgtokyo) November 16, 2019
Main Sessionにて柴田 芳樹さんにご講演いただきます。『マイクロサービスの開発とテストファースト/テスト駆動開発』と題して、merpayのバックエンドエンジニアとしてどのような手順で開発し工夫をしているのかなど紹介いただきます。 #DevFest19 #gdgtokyo pic.twitter.com/IZG1rglNCT
2023-11-08 17:12
コメント(0)

著書(PDF)
")


翻訳本(Kindle版)




翻訳本(PDF)















")

